")






Learning subseasonal-to-seasonal global ocean forecasting on a hierarchical triangle mesh
Ocean Sciences, Climate
Research area
Numerical weather prediction (NWP) models have improved in medium-range forecasting, but longer-term forecasts (two weeks to three months) are crucial for planning and risk mitigation.
Subseasonal-to-seasonal (S2S) forecasts are inherently probabilistic due to the chaotic nature of the atmosphere. Traditional ensemble-based NWP approaches face limitations, while machine learning weather prediction (MLWP) models offer advantages, such as improved accuracy from historical data and computational efficiency in uncertainty quantification.
However, improving S2S forecasting requires better ocean modeling, as ocean-atmosphere coupling becomes dominant at these timescales. Few data-driven ocean models exist, presenting an opportunity to develop ML-based global ocean forecasting for S2S timescales.
Project goals
Graph Neural Networks (GNNs) have been proven effective for deep-learning global weather forecasting, but this leaves open the question of whether this architecture can be applied to ocean modelling, where the dynamics is heavily influenced by the interactions with coastlines.
The main objective of the project is to prove that a model based on GNNs can be successfully trained on a dataset based on GLORYS12, a global ocean circulation reanalysis provided by the Copernicus Marine Service, on a par with what state-of-the-art weather models did with ERA5.
Ocean dynamics is relevant for subseasonal-to-seasonal scale weather forecasting, and the development of the proposed model is a step forward in the direction of a data-driven Earth system model. However, the proposed model would be valuable per se, e.g. fostering the inclusion of marine biogeochemical variables into data-driven models, which are needed for compound hazard estimation in the marine environment and carbon sequestration modelling, just to name a few.
Computational approach
Datasets derived from atmospheric and ocean reanalyses for training data-driven models have sizes ranging from hundreds of gigabytes to terabytes, which is comparable with language models datasets.
However, unlike the case of the latters, each sample from these datasets is a rather large tensor, whose processing require optimization techniques like gradient checkpointing and reduced precision to fit into GPU memory.
Finally, multi-node/multi-GPU systems and other optimizations, such as overlapping CPU pre-processing of samples with GPU gradient computations, are required to feasibly train these models.
Image
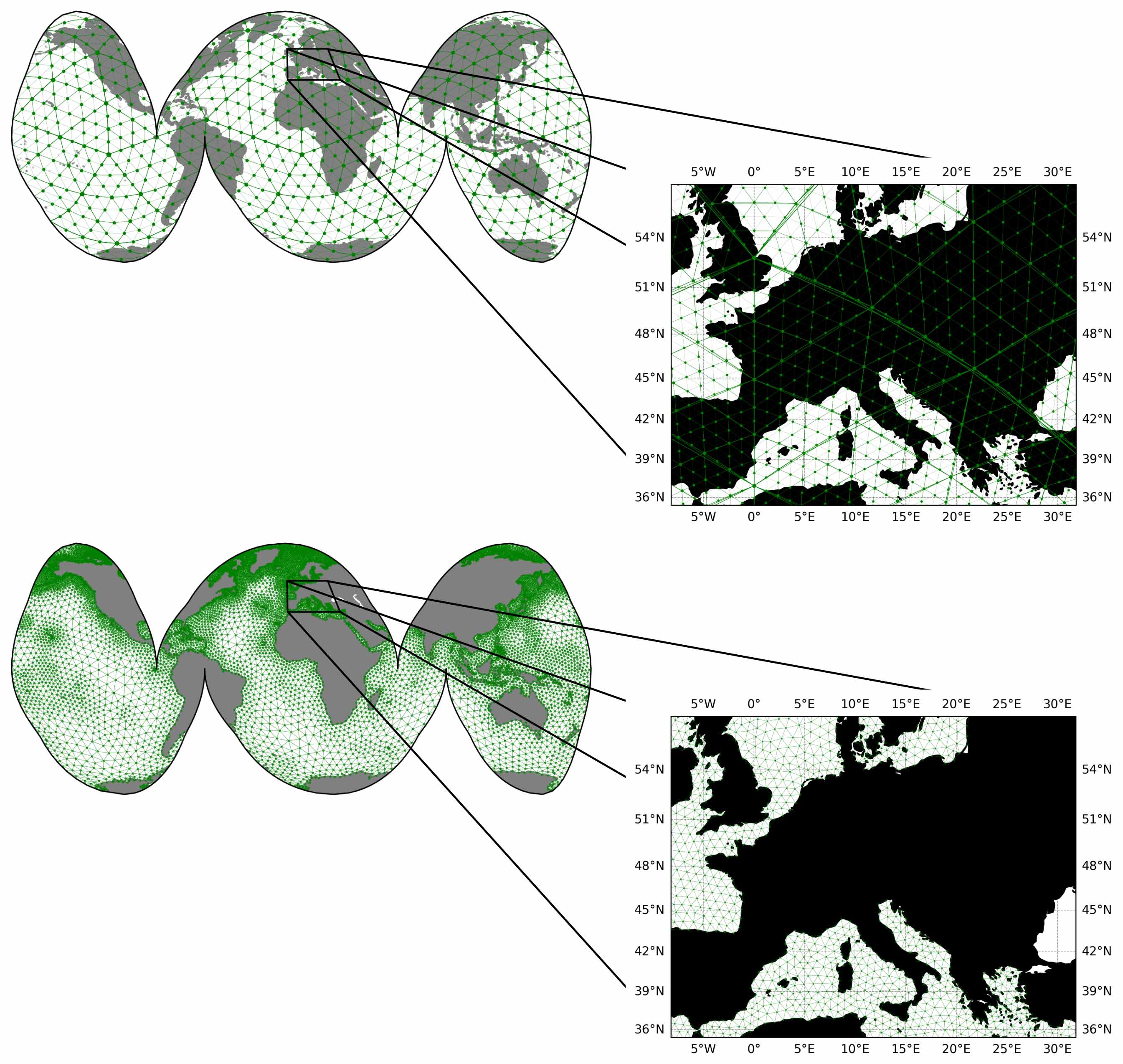
Comparison between GraphCast and proposed triangle mesh-graphs.
Stefano Campanella
Istituto Nazionale di Oceanografia e di Geofisica Sperimentale
I am a research software engineer working on Earth and environmental science with experience in hydrology, seismology, and computational oceanography.
My interests include high-performance computing, modern programming techniques, and data-driven modelling.